Evaluating LLMs is hard. Many popular benchmarks have become saturated, leading to artificial inflation of the ability of models to solve complex problems. These issues are exacerbated by the incentive that exists for AI people to constantly hype the field. A recent example of an OpenAI exec claiming that ChatGPT had solved ten open Erdős problems when it had in fact just found existing papers discussing their solutions springs to mind.
The problem with many current benchmarks is that as soon as they are used once, they become stale. Because frontier models are closed, test problems must be revealed to the companies that own them for a benchmark to be evaluated. After the problems have been revealed the companies can train the models to perform well on them, in order to make their model look better. Unfortunately for us in the general public, this makes it difficult to assess the quality of models in an unbiased way. Leaderboards like LM arena, which directly measure human preferences, go some way to addressing these issues, but for complex problems finding sufficiently qualified raters is challenging. These leaderboards also have their own issues with bias.
What, then, is to be done? If only there was an ever-changing environment that could be easily represented numerically, where there was no possibility of cheating, the outcome was clearly measurable and success hinged on pure intellect! Enter Alpha Arena. The idea behind this newly introduced benchmark is that we just let LLMs loose in the market and see which one makes the most profit. In order to make things tractable, the model is only allowed to trade from a set of 6 crypto assets on a specific exchange at intervals of 3 minutes. Information about the state of the market, the model’s current position, and the overall goal is put into a prompt at each time step, and the model is asked to produce a decision to buy, sell, or hold. The exact details of how this works can be found this blog post, which is worth a read.
On its face, this seems to be a bit crazy, especially for anyone with experience developing trading algorithms. I want to say before I get into the weeds, that I actually don’t think this is the worst idea ever, at least for benchmarking.1 There have been a surprising number of tasks that can be solved pretty OK-ish by just whacking it in the prompt, and it would be cool to see if that might work here. Five years ago people would have laughed you out of town for suggesting doing machine learning in this way. If an LLM could trade well, and importantly this could be shown in a statistically reliable way, that would be an important finding, and would have interesting implications for markets. It might also measure a different aspect of “intelligence” that current benchmarks fail to capture.
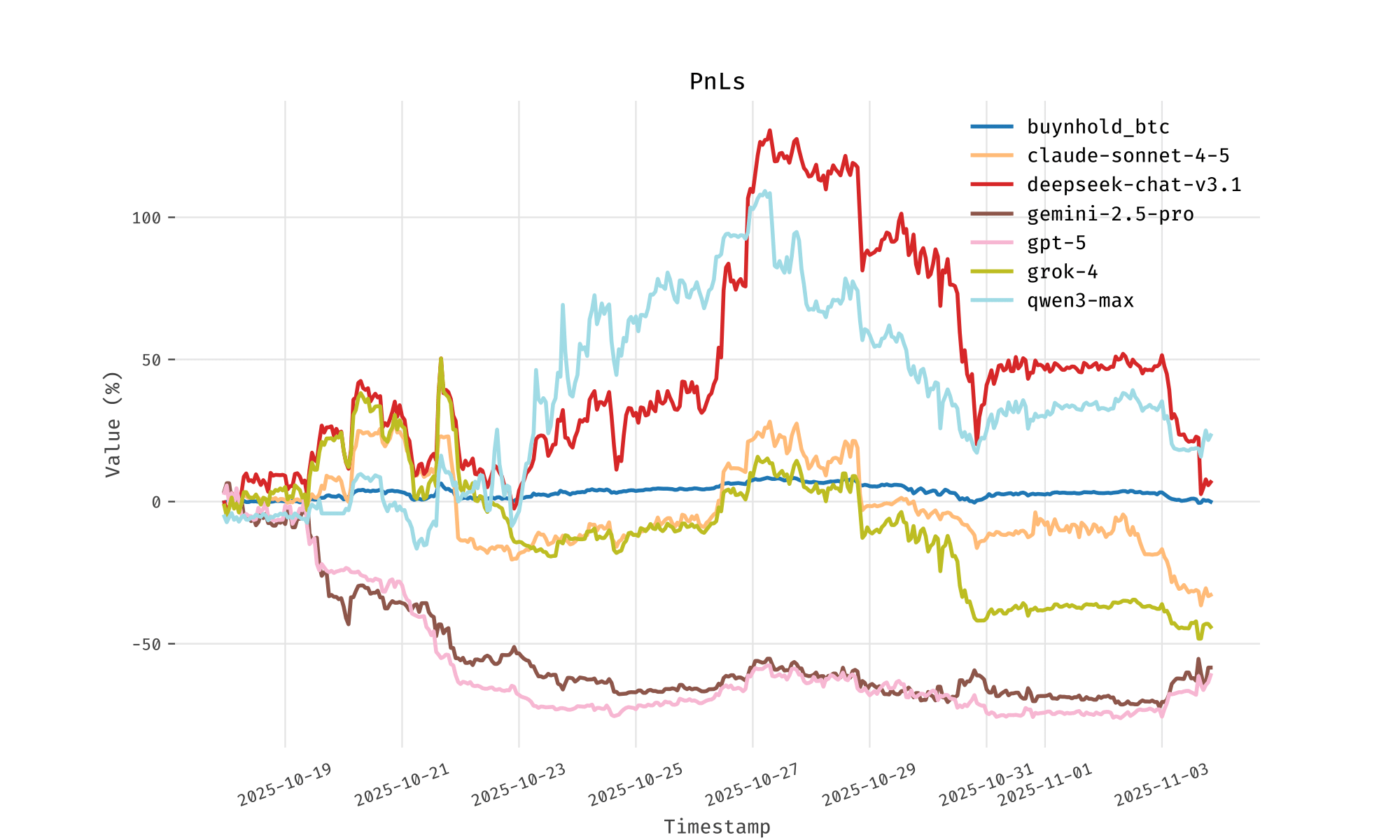
That being said, I am skeptical that there is any evidence from this iteration of the benchmark that any of these LLMs can trade skilfully. The final PnL charts are are shown above. All of the LLMs but Deepseek and Qwen ended with negative PnL, with ChatGPT and Gemini in particular losing a large proportion of the initial $10,000 capital. Deepseek and Qwen only made small gains, relative to the high volatility over the testing period. You don’t really need Sharpe ratios to say that the models are failing.
Originally I started drafting this post midway through the competition when a couple of the models had made decent money (around 2025-10-27 both Deepseek and Qwen had more than doubled the initial capital). I was planning to very wisely and smugly point out that it would not be unlikely to get this kind of result from trading randomly, with no skill whatsoever. I wrote a simple backtester for a random trading strategy on the same set of assets, with similar leverage and trading frequency. The results showed that, as suspected, a PnL as good as the best model was expected to happen in about 10% of cases, below the level generally considered to be significant (if you believe in the concept of p-values).
Unfortunately for me, all of that was basically pointless because pretty soon after I had written my nice backtest, the markets turned and all the models started losing money. By looking at the final PnL charts it is pretty clear that you wouldn’t trust any of the models with your savings, or even a much more fleeting sum, no analysis required. I still want to show off the nice chart I made, the left shows sample paths from my random strategy, and the right shows the distribution of final random PnLs along with the PnLs of each of the models. It’s clear that none of the models are doing anything better than random; the sample paths of the simulation look pretty similar to the LLMs.
If the initial hypothesis of the Alpha Arena benchmark was that LLMs could trade skilfully, there is very little supporting evidence for that here. In fairness, the organisers themselves are quite open about this, and aren’t making as many outlandish claims as is standard in AI land. They have done some analysis that shows that each of the models seems to have distinct trading patterns, but it feels like this might just be a result of the different token bias in each model, not something deeper.
It’s difficult to say if this problem is just much too hard to be solved by any model of this kind (I suspect this is true), or the models just aren’t good enough yet, or there is something about the setup that is holding the models back. One thing I think would be interesting to look at is the inclusion of qualitative information, like Twitter feeds, news etc. The way the information is presented to the models in the current setup feels like putting a square peg in a round hole, and there is potential to extract richer information in a more natural way than just putting lagged indicators in the prompt. It would also be cool to look at doing RL post-training based on feedback from the market. Despite my skepticism of this ever working, I find myself somewhat interested to see what happens in round 2!
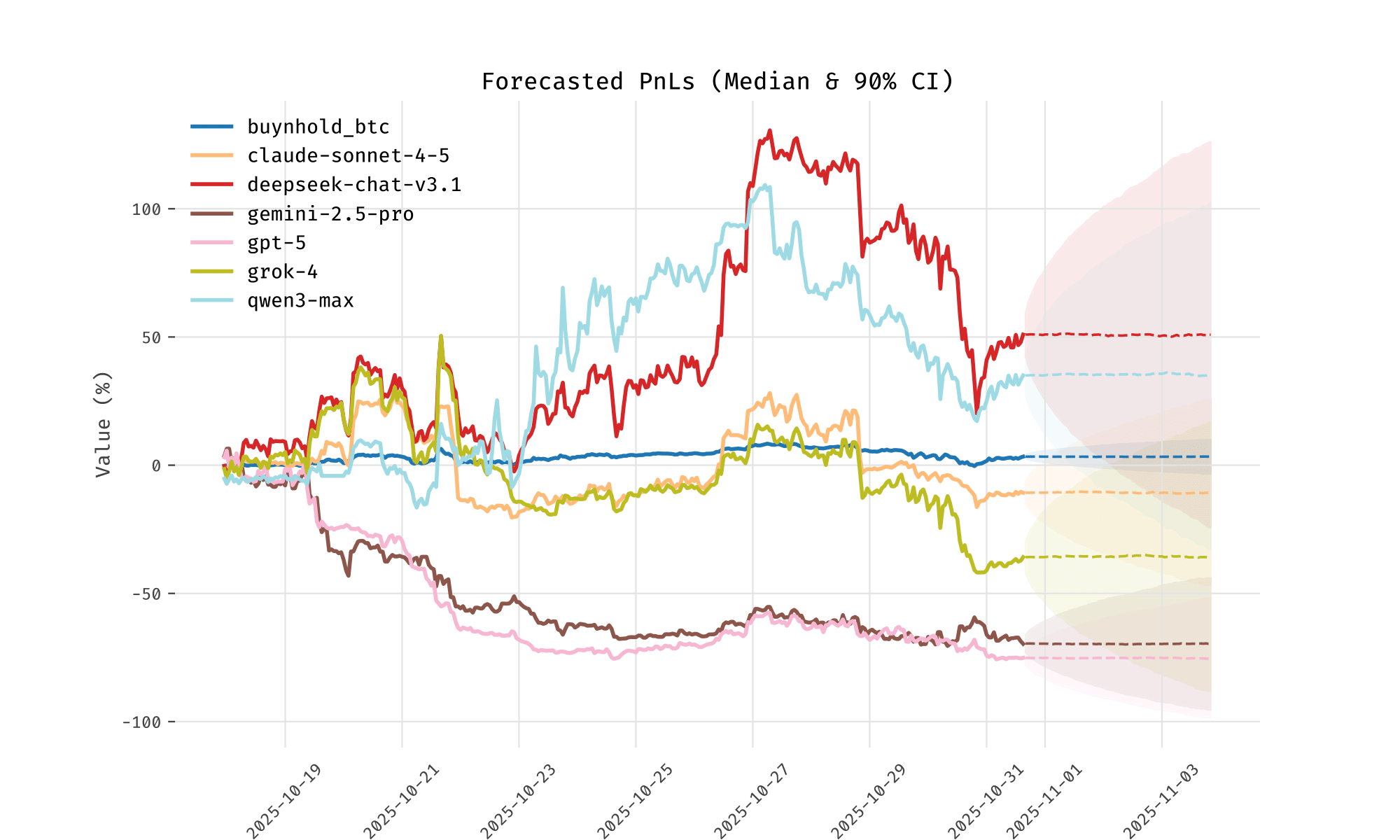
Polymarket Bonus Ball
In the sick, broken world that we live in, it was actually possible to trade the outcomes of this experiment on Polymarket, who provided markets on “Biggest winner”, “Biggest loser” and “Will anyone hit 50k?”.2 Whilst the competition was ongoing I used a simple exponential smoothing model to predict paths for the PnLs up until the end of the competition, and determine the probability of each model losing. On the 2025-10-31, the chance of Grok losing was priced at 1 cent (implying 1% chance), whereas my model said there was about a 9% chance. I ploughed the princely sum of 1 USDC into Grok “Yes” tokens, with a potential payout of $100. Unfortunately it didn’t go my way and I lost the cash, making this blog post much less good, and smug, in the process. The forecasts are below. You can make up your own mind as to whether this was a good bet or not.