Recently I’ve been thinking a bit about foundation models for time series, and I can’t work out how to feel about them. Are they the right approach? Has everyone just got foundation model fever? This post provides a semi-structured set of these thoughts, and unfortunately raises more questions than it provides answers.
Time series foundation models (FMs) are trained on large collections of time series from diverse domains. The commonly used GIFT-Eval pretrain set, for example, is almost 1TB of series, everything from bitcoin prices to climate sims to server logs. The assumption implicit in the foundation modelling paradigm is that there should be positive transfer across these domains, that is to say, that training the model on the data from all the domains at once should provide better performance on a given domain than training a model with the same compute budget on data from the domain alone. Negative transfer occurs when the performance on a single domain is lower when training on the whole corpus vs just that domain’s data.
It’s first important to establish exactly what problem we are trying to solve by using a foundation model as opposed to any other model. I will assume that we are operating in domain X, and our goal is to get the best possible forecasts for our set of series from domain X. I believe this is the goal of most practitioners who will be practically using these models. Note that it’s possible your goal is to get many forecasts for many domains quickly, or wish to have a single model that is easy to deploy and serve. In this case it may be that you are willing to accept some hit in performance for the convenience of using a universal model. This convenience point will not be addressed but is a valid reason for the paradigm existing.
Conceptually, it does seem somewhat strange to group together time series as a modality, when they can come from such diverse sources. This issue is discussed by Dai et al. (2026) who call it a category error to consider time series as a modality, instead of a data type. They argue that there is no semantic relationship between a spike in an ECG and a spike in a stock price, and so training on one shouldn’t help us with the other, unlike in e.g. language modelling where the structure of language transfers across different tasks. Unfortunately the authors don’t offer any evidence in the form of experiments to substantiate their argument. This type of argument has also been made by others in the past.
The most relevant empirical evidence for negative transfer appears in a nice paper from Zhang et al. (2025). In their paper they take a small FM architecture and choose a number of domains, most of which have multiple datasets. They first fit the model on all the datasets and run the evaluation. They then take all the ordered pairwise combinations of datasets, and fit a model on both datasets combined, and then evaluate on the first dataset. You can see the results in the table below, which shows the percentage change in test loss when training on both datasets and evaluating on the row datasets when compared with simply training in the row dataset alone. The “all” column shows the result of training on all the datasets.
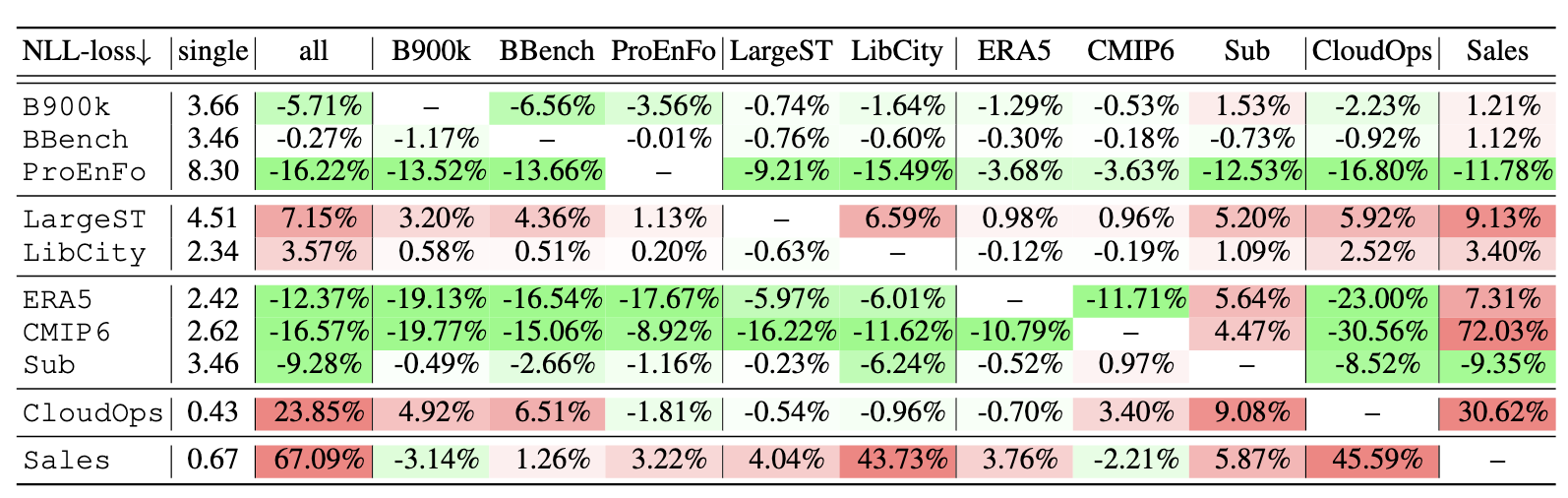
Cross domain training results from Zhang et al. (2025).
There is lot of interesting stuff going on here, and it’s worth taking a look at the paper for a full analysis, but I want to highlight a few things. Firstly, we can see that the full pre-training, with all the datasets only actually helps for half the datasets, for the others it either does nothing, or hurts a lot (CloudOps and Sales). This is strong evidence for the negative transfer hypothesis, at least for some datasets. Secondly, the results are not symmetric, meaning the fact that training on datasets A + B helps performance on dataset A does not also imply that it helps on dataset B (see Sub and Sales). The authors make the point this might be caused by the difference in sampling frequencies between the datasets. Finally, we should also note that the effects are not consistent within a domain; none of the additional datasets has a significant positive effect on the BBench scores, but all of them do for the ProEnFo, even though both of these datasets are related to energy usage.
Some caveats to these results: they are using a smaller model variant (10M parameters) so this may affect the ability of the model to adequately cover all the domains at once. Also, it is not exactly clear to me how we should adjust for datasets size in these experiments, for example the BBench dataset has 10x the number of points as ProEnFo, even though they are both sampled at the same frequency.
We can also get some evidence from re-analysing the results of the models on FEV bench, a diverse benchmark of time series problems popular with the community. Despite the fact that, for some reason, task specific deep learning models are not included, the traditional non-foundation model baselines1 provide equivalent or better performance for 17/100 tasks. For me this is a significant number, and is cause for at least some concern. The aggregated statistics that are often centred in these papers kind of ignore this. Can a model be truly foundational if it fails to beat simple baselines on such a high proportion of tasks? Maybe? This is something I can’t make my mind up about, but it is definitely different from other domains like language. No one is using n-gram models for real tasks these days!
All that being said, the number one argument for using FMs for time series is that they do seem to give very strong empirical performance on certain domains relative to other available models. In particular when there is complex periodicity or non-stationarities which cause simpler models to fail. There does truly seem to be something going on here that is useful.
The no-free lunch theorem is something people in ML love to bring up at every possible opportunity, even when it isn’t really relevant (see also The Bitter Lesson™️). In a sense this is sort of the argument that Dai et al. (2026) are making: we can’t have one model that works well for all tasks at once. There was a really nice paper from Andrew Gordon Wilson’s group a few years ago that pushed back on the applicability of the no free lunch theorem to LLMs by pointing out that it might not actually be the case that foundation models are trying to achieve good performance on all tasks. Perhaps the set of tasks we care about is actually a small subset of the distribution of all possible tasks, and it is possible to have a model that works well on that subset?
If that’s the case, then it matters a lot which subset we choose. Practically, it is also true that there are common features that span different time series domains that are on the surface unrelated. For example both energy and transport are both heavily influenced by the weather, which (obviously!) exhibits regular seasonality. Perhaps it’s enough to just fit the model on these related domains, and drop the others. It looks like things might be going this way. The pre-training dataset used for Chronos 2, one of the currently hot models, does away with the huge pre-train corpus and uses a much more well-curated subset, augmented with synthetic data. This subset notably contains mostly climate, transport, and energy series, and doesn’t contain large amounts of e.g. financial or health data of dubious predictability.
The trend in training these models does seem to be to use increasing amounts of synthetic data, with certain models providing strong performance when trained on synthetic data alone. The question then shifts to how the simulator is constructed. Is it best to fit one model on data from one setting of the simulator? Or can we get better results by using different simulators for different domains or sets of domains? This is something that hasn’t been addressed in the literature.
So where does all that leave us? I think the honest answer is that it’s still not clear whether the foundation model paradigm is the right one for time series. The evidence for negative transfer is real and shouldn’t be hand-waved away, but these models are genuinely useful in a lot of settings. Perhaps we can get the best of both worlds by using curated, domain-aware pretraining sets and synthetic data? Whether that still counts as “foundational” is another question entirely.
-
These include stats models like ETS and linear AR, as well as running gradient boosting models on lagged series. ↩︎